本文最后更新于:14 天前
Request库
使用 Requests 发送网络请求非常简单。
requests.get()
requests.get(url, params=None, **kwargs)获取HTML网页的主要方法,对应于HTTP的GET.
构造一个向服务器请求资源的Request对象
返回一个包含服务器资源的Response对象.
help(requests.get)Sends a GET request.
:param url: URL for the new :class:Requestobject.
:param params: (optional) Dictionary or bytes to be sent in the query string for the :class:Request.
:param **kwargs: Optional arguments thatrequesttakes.
:return: :class:Response <Response>object
:rtype: requests.Response
发送GET请求。
url:拟获取页面的url链接
params:url中的额外参数,字典或字节流格式,可选
**kwargs:12个控制访问的参数
普通get
In [22]: import requests
In [23]: url
Out[23]: 'https://www.baidu.com'
In [24]: r = requests.get(url)
Out[24]: <Response [200]>
In [27]: r.url
Out[27]: 'https://www.baidu.com/'带参get
In [41]: r = requests.get(url+'/s', params={'wd':'dog'})
In [42]: r.url
Out[42]: 'https://www.baidu.com/s?wd=dog'requests.head()
获取HTML网页头信息的方法,对应于HTTP的HEAD
requests.head(url, **kwargs)url:拟获取页面的url链接
**kwargs:13个控制访问的参数
requests.post()
向HTML网页提交POST请求的方法,对应于HTTP的POST
requests.post(url, data=None, json=None, **kwargs)url:拟获取页面的url链接
data:字典、字节序列或文件,Request的内容
json:JSON格式的数据,Request的内容
**kwargs:11个控制访问参数
requests.put()
向HTML网页提交PUT请求的方法,对应于HTTP的PUT
requests.put(url, data=None, **kwargs)url:拟更新页面的url链接
data:字典、字节序列或文件,Request的内容
**kwargs:12个控制访问参数
requests.patch()
向HTML网页提交局部修改请求,对应于HTTP的PATCH
requests.patch(url, data=None, **kwargs)url:拟更新页面的url链接
data:字典、字节序列或文件,Request的内容
**kwargs:12个控制访问参数
requests.delete()
向HTML页面提交删除请求,对应于HTTP的DELETE
requests.delete(url, **kwargs)url:拟删除页面的url链接
**kwargs:13个控制访问参数
response对象的属性
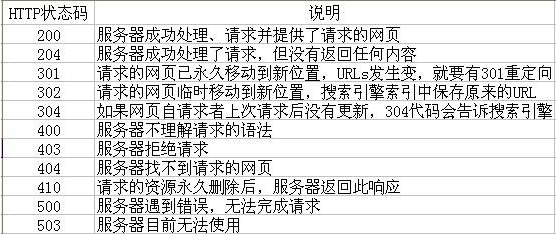
r.status_code
HTTP请求的返回状态,200表示连接成功,404表示失败
r.text
HTTP响应内容的字符串形式,即,url对应的页面内容
r.emcoding
从HTTPheader中猜测的响应内容编码方式
r.apparent_encoding
从内容分析出的响应内容编码方式(备选编码方式).
r.content
HTTP响应内容的二进制形式.
理解Response的编码
r.encoding
从HTTP header中猜测的响应内容编码方式
注意:如果header中不存在charset,则认为编码为ISO-8859-1。
r.apparent_encoding
从内容中分析出的响应内容编码方式(备选编码方式)
注意:根据网页内容分析出的编码方式
理解Requests库的异常
requests.ConnectionError
网络连接错误异常,如DNS查询失败、拒绝连接等
requests.HTTPErrorHTTP
错误异常
requests.URLRequired
URL缺失异常
requests.TooMangRedirects
超过最大重定向次数,产生重定向异常
requests.ConnectTimeout
连接远程服务器超时异常
requests.Timeout
请求URL超时,产生超时异常
r.raise_for_status()
如果不是200,产生异常requests.HTTPError
爬取网页的通用代码框架
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status() #如果状态不是200,引发HTTPError异常#
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__ == "__main__":
url = "http://www.baidu.com"
print(getHTMLText(url))HTTP协议对资源的操作

request.request()
requests.request(method, url, **kwargs)
method:请求方式
url:拟获取页面的url链接
r = requests.request('GET', url, **kwargs)
r = requests.request('HEAD', url, **kwargs)
r = requests.request('POST', url, **kwargs)
r = requests.request('PUT', url, **kwargs)
r = requests.request('PATCH', url, **kwargs)
r = requests.request('DELETE', url, **kwargs)
r = requests.request('OPTIONS', url, **kwargs)
**kwargs:控制访问的参数,均为可选项,共13个超参数
params
字典或字节序列,作为参数增加到url中
kv = {'key1': 'value1', 'key2': 'value2'}
r = requests.request('GET', 'http://python123.io/ws', params=kv)
print(r.url)https://python123.io/ws?key1=value1&key2=value2data
字典、字节序列或文件对象,作为Request的对象
body = '主体内容'.encode('utf-8')
r = requests.request('POST', 'http://python123.io/ws', data=body)
print(r.url)http://python123.io/wsjson
JSON格式的数据,作为Request的内容
kv = {'key1': 'value1'}
r = requests.request('POST', 'http://python123.io/ws', json=kv)
print(r.url)http://python123.io/wsheaders
字典,HTTP定制头
hd = {'user-agent': 'Chrome/10'}
r = requests.request('POST', 'http://python123.io/ws', headers=hd)
print(r.url)http://python123.io/wscookies
字典或CookieJar,Request中的cookie
auth
元组,支持HTTP认证功能
files
字典类型,传输文件
fs = {'file': open('data.xls','rb')}
r = requests.request('POST', 'http://python123.io/ws', files=fs)
print(r.url)timeout
设定超时时间,秒为单位
r = requests.request('GET', 'http://www.baidu.com', timeout=10)proxies
字典类型,设置访问代理服务器,可以增加登录认证
pxs = {'http': 'http://user:pass@10.10.10.1:1234'
'https': 'https://10.10.10.1:4321'}
r = requests.request('GET', 'http://www.baidu.com', proxies=pxs)allow_redirects
True/False,默认为Ture,重定向开关
stream
True/False,默认为True,获取内容立即下载开关
verify
True/False,默认为True,认证SSL证书开关
cert
本地SSL证书路径
爬虫案例
网站
实例网站:百度图片搜索
分析网页
搜索关键字:猫
https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&fm=index&pos=history&word=%E7%8C%AB搜索关键字:狗
https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&fm=index&pos=history&word=%E7%8B%97对比get的网址,发现只有搜索关键字不一样。
获得网页数据
我们就才有前面提到的通用的代码框架
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status() # 如果状态不是200,引发HTTPError异常#
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__ == "__main__":
key_word = '小狗'
url = 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&sf=1&fmq=&pv=&ic=0' \
'&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&fm=index&pos=history&word='
html = getHTMLText(url+key_word)
print(html)通用代码框架加上我们刚刚分析网址get的请求网址,就可以获取到网页的数据。
处理数据
接下来就是处理数据,把我们所需要的图片网址匹配出来
通过F12找到图片的网址–这个不是原图地址
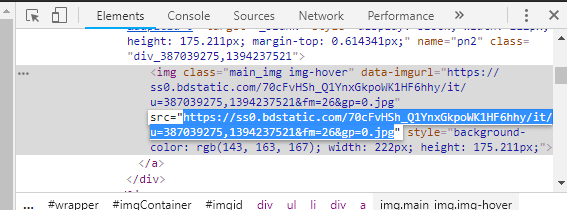
右键 查看网页源代码,分析JSON数据可知,其中的字段objURL,即表示了原图的下载地址。
通过正则在代码里匹配出图片的网址
pic_urls = re.findall('"objURL":"(.*?)",', html, re.S)
print(pic_urls)展示结果
def down(urls):
for i, url in enumerate(urls):
try:
pic = requests.get(url, timeout=15)
string = str(i + 1) + '.jpg'
with open(string, 'wb') as f:
f.write(pic.content)
print('成功下载第%s张图片: %s' % (str(i + 1), str(url)))
except Exception as e:
print('下载第%s张图片时失败: %s' % (str(i + 1), str(url)))
print(e)
continue通过访问我们获取到的图片网址,对图片进行保存。
完整代码
import requests
import re
def getHTMLText(url):
"""
获取网页数据
:param url: 访问网址
:return:
"""
try:
r = requests.get(url, timeout=30)
r.raise_for_status() # 如果状态不是200,引发HTTPError异常#
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常"
def down(urls):
"""
下载图片
:param urls: 图片网址列表
:return:
"""
for i, url in enumerate(urls):
try:
pic = requests.get(url, timeout=15)
string = str(i + 1) + '.jpg'
with open(string, 'wb') as f:
f.write(pic.content)
print('成功下载第%s张图片: %s' % (str(i + 1), str(url)))
except Exception as e:
print('下载第%s张图片时失败: %s' % (str(i + 1), str(url)))
print(e)
continue
if __name__ == "__main__":
key_word = '小狗'
url = 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&sf=1&fmq=&pv=&ic=0' \
'&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&fm=index&pos=history&word='
html = getHTMLText(url+key_word)
urls = re.findall('"objURL":"(.*?)",', html, re.S) # 匹配原图地址
print(len(urls))
down(urls)本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!