本文最后更新于:14 天前
NLP之命名实体识别(NER)
实体概念
百度百科:实体(entity)指客观存在、并可相互区别的事物。实体可以是具体的人、事、物,也可以是概念。
【栗子】
文本:我爱北京天安门
实体:北京 天安门
命名实体
命名实体就是以
名称为标识的实体。通俗来讲:我们听到一个名字,就能知道这个东西是哪一个具体的事物,那么这个事物就是命名实体。
从编程语言的角度讲:类的一个实例,就是一个命名实体。
【常见的命名实体】
学术上NER所涉及的命名实体一般包括3大类(实体类,时间类,数字类)和7小类(人名、地名、组织机构名、时间、日期、货币、百分比)。
| 实体 | 实体类型 |
|---|---|
| 2019年11月23日 | 时间表达式 |
| 成都 | 地名 |
| 元旦节 | 节日 |
| 张三,李四 | 人名 |
| 1,2,3,4,5 | 数字 |
| 无糖信息 | 组织机构 |
命名实体的应用
命名实体是现实世界里的事物,它们和现实世界相互作用、相互影响,因此命名实体在一些场景里特别重要。
关系抽取:我们需要知道事物之间的关系,进而准确地决策
摘要生成:简历往往比较详细,我们只需要通过只提取主要实体(如姓名、教育背景、技能等)来应用它来自动生成简历摘要,来进行简历自动汇总。
优化搜索引擎算法:对文章运行一次NER模型,并永久存储与之相关的实体。然后,可以将搜索查询中的关键标记与与网站文章关联的标记进行比较,以实现快速高效的搜索。
【总结】
NER任务是很多任务的基础,被广泛地应用到了以下的领域中:
信息抽取
关系抽取
语法分析
信息检索
问答系统
机器翻译
…
命名实体标注
命名实体标注任务的流程图。我们将原始文本输入到NER工具里,该工具会输出带有命名实体标记的文本或者命名实体列表。
【标注工具】
【标注流程】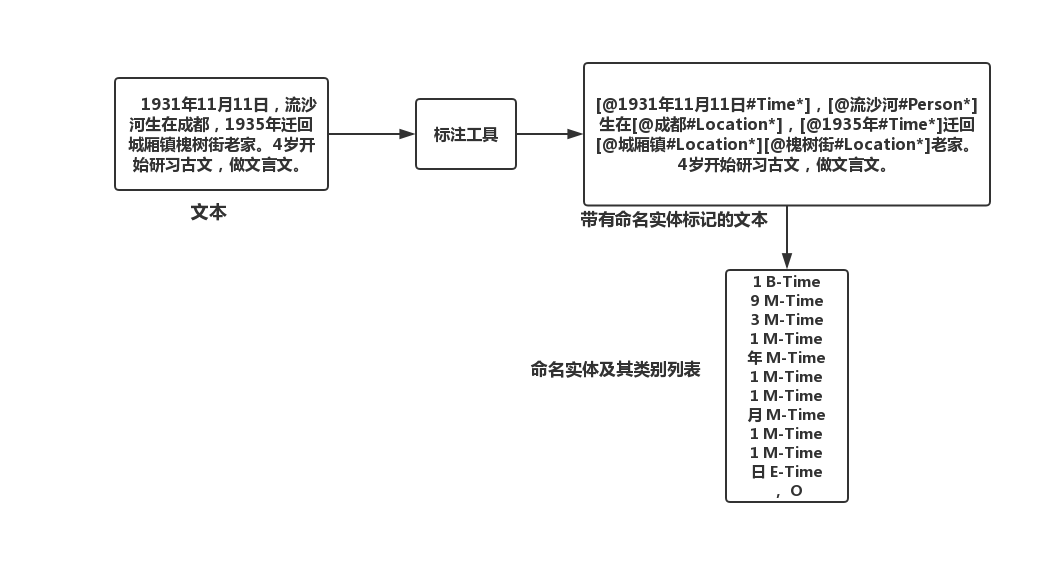
【标签体系】

【栗子】

命名实体识别
【基于nlpir】
【栗子】
import pynlpir
pynlpir.open()
msg = “张伟是四川成都人,身份证号是:123456700000000000”
print(pynlpir.segment(msg, pos_names=’all’))
[(‘张伟’, ‘noun:personal name’), (‘是’, ‘verb:verb 是’), (‘四川’, ‘noun:toponym’), (‘成都’, ‘noun:toponym’), (‘人’, ‘noun’), (‘,’, ‘punctuation mark:comma’), (‘身份证’, ‘noun’), (‘号’, ‘classifier’), (‘是’, ‘verb:verb 是’), (‘:’, ‘punctuation mark:dash’), (‘123456700000000000’, ‘numeral’)]
其中:personal name为人名、toponym为地名, numeral为数字。
【基于深度学习算法】
算法:transformer+blstm+crf
content: 李文兴:1958年8月出生,男,中国国籍,博士研究生学历,本公司独立董事。
NER识别结果: NAME: 李文兴 CONT 中国国籍 EDU: 博士研究生学历 ORGANIZATION: 本公司 TITLE: 独立董事
【其他算法】
参考:https://github.com/chineseGLUE/chineseGLUE
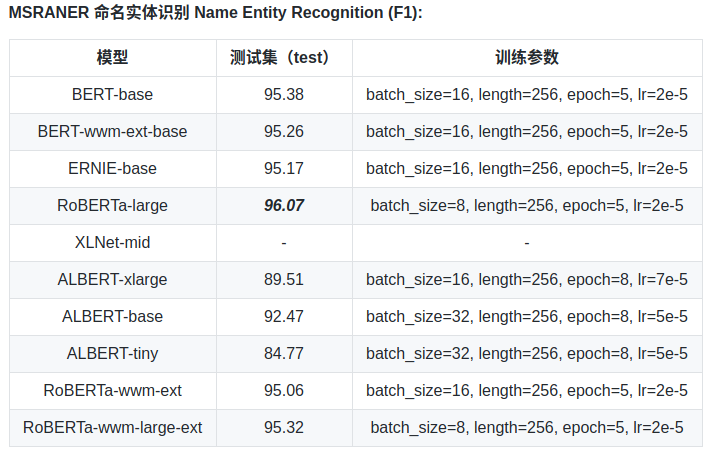
相关工具参考
| 工具 | 简介 | 访问地址 |
|---|---|---|
| Stanford NER | 斯坦福大学开发的基于条件随机场的命名实体识别系统,该系统参数是基于CoNLL、MUC-6、MUC-7和ACE命名实体语料训练出来的。 | 官网 |
| MALLET | 麻省大学开发的一个统计自然语言处理的开源包,其序列标注工具的应用中能够实现命名实体识别。 | 官网 |
| Hanlp | HanLP是一系列模型与算法组成的NLP工具包,由大快搜索主导并完全开源,目标是普及自然语言处理在生产环境中的应用。支持命名实体识别。 | 官网 |
| NLTK | NLTK是一个高效的Python构建的平台,用来处理人类自然语言数据。 | 官网 |
| SpaCy | 工业级的自然语言处理工具,遗憾的是不支持中文。 | 官网 |
| Crfsuite | 可以载入自己的数据集去训练CRF实体识别模型。 | 文档 |
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!