本文最后更新于:14 天前
论文原文
链接:Rich feature hierarchies for accurate object detection and semantic segmentation

RCNN作为第一篇目标检测领域的深度学习文章,大幅提升了目标检测的识别精度,在PASCAL VOC2012数据集上将MAP从35.1%提升至53.7%。使得CNN在目标检测领域成为常态,也使得大家开始探索CNN在其他计算机视觉领域的巨大潜力。这篇文章的创新点有以下几点:将CNN用作目标检测的特征提取器、有监督预训练的方式初始化CNN、在CNN特征上做BoundingBox 回归。
摘要
从ILSVRC 2012、2013表现结果来看,CNN在计算机视觉的特征表示能力要远高于传统的HOG、SIFT特征等,而且这种层次的、多阶段、逐步细化的特征计算方式也更加符合人类的认知习惯。但是,如何将在目标检测领域重现这种奇迹呢?目标检测区别于目标识别很重要的一点是其需要目标的具体位置,也就是BoundingBox。而产生BoundingBox最简单的方法就是滑窗,可以在卷积特征上滑窗。
但是我们知道CNN是一个层次的结构,随着网络层数的加深,卷积特征的步伐及感受野也越来越大。例如AlexNet的Pool5层感受野为195*195,步伐为32*32,显然这种感受野是不足以进行目标定位的。使用浅层的神经网络能够保留这种空间结构,但是特征提取的性能就会大打折扣。
RCNN另辟蹊径,既然我们无法使用卷积特征滑窗,那我们通过区域建议方法产生一系列的区域,然后直接使用CNN去分类这些区域是目标还是背景不就可以吗?当然这样做也会面临很多的问题,不过这个思路正是RCNN的核心。因此RCNN全称为Regions with CNN features。
网络结构

结构流程
【基本流程】
RCNN算法分为4个步骤
- 候选区域生成: 一张图像生成2K个候选区域 (采用Selective Search 方法)
- 统一候选区域尺寸:将每个区域固定成227*227的尺寸送入CNN进行特征提取
- 特征提取: 对每个候选区域,使用深度卷积网络提取特征 (CNN)
- 类别判断: 特征送入每一类的SVM 分类器,判别是否属于该类
- 位置修正:回归器校正非极大值抑制后剩下的region proposal
【region proposals】
输入一张多目标图像,采用
selective search算法提取约2000个region proposals
selective search
算法流程
使用Efficient GraphBased Image Segmentation算法分割图像得到多个region.
计算每两个region的相似度.
合并相似度最大的两个region.
计算新合并region与其他region的相似度,合并相似度最大的两个region.
重复上述过程直到整张图片都聚合成一个大的region.
使用一种随机的计分方式给每个region打分,按照分数进行ranking,取出top k的子集,就是selective search的结果(k=2000)

【crop】
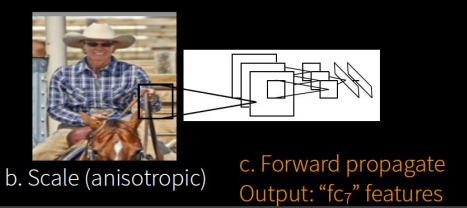
在每个region proposal周围加上16个像素值为region proposal像素平均值的边框,再直接变形为227×227的size


作者提出了两种形变方式

各向异性缩放
各向异性缩放就是,不管图像是否扭曲,直接将图像缩放到固定大小,如图D所示.
各向同性缩放
- 将图像在原图中沿着bounding box进行扩展,如果已经延伸到了原始图片的外边界,那么就用bounding box中的颜色均值填充,如图B所示.
- 将图像用固定的背景填充,如图C所示.
【Compute CNN Feature】
【预处理操作】
- 将所有region proposal像素减去该region proposal像素平均值,
【AlexNet CNN】
- 再依次将每个227×227的region proposal输入
AlexNet CNN网络获取4096维的特征【比以前的人工经验特征低两个数量级】,2000个建议框的CNN特征组合成2000×4096维矩阵;
【linear classifiers】
- 将2000×4096维特征与20个SVM组成的权值矩阵4096×20相乘【20种分类,SVM是二分类器,则有20个SVM】,获得2000×20维矩阵表示每个region proposal是某个物体类别的得分

【NMS】
分别对上述2000×20维矩阵中每一列即每一类进行非极大值抑制剔除重叠region proposal,得到该列即该类中得分最高的一些region proposal
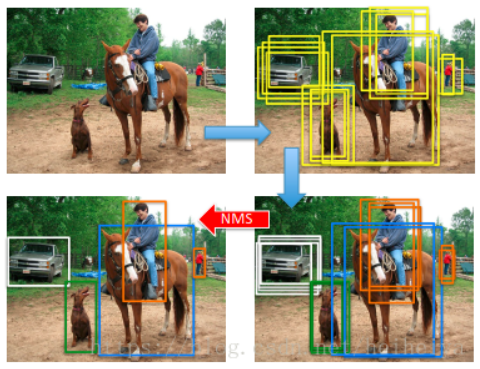
算法流程
假设有有一个候选的boxes的集合, IOU阈值Nt:
- 假设有6个候选框,根据分类器类别分类概率做排序,从小到大的概率分别为A、B、C、D、E、F。
- 从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于Nt
- 假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
- 从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
- 重复1-4,直到找到所有需要被保留下来的矩形框。

【Bbox Regression】
- 分别用20个回归器对上述20个类别中剩余的region proposal进行回归操作,最终得到每个类别的修正后的得分最高的bounding box。

网络训练
对CNN的有监督预训练:在ILSVRC样本集(只有分类标签)上对CNN网络进行有监督预训练,此时网络最后的输出是4096维特征->2000类分类的映射。
特定样本下CNN的微调:即domain specific fine-tuning, 在本文中是在PASCAL VOC 2007上进行,学习率是第1步预训练学习率的1/10,将第1步中的1000类分类输出改为21类(20类+背景),注意此处仍然是softmax,而不是SVM。
- 正样本:Ground Truth+与Ground Truth相交IoU>0.5的Region proposal
- 负样本:与Ground Truth相交IoU≤0.5的建议框
每一类的SVM的训练:输入正负样本在CNN网络计算下的4096维特征(fc7层)
正样本:Ground Truth
负样本:与Ground Truth相交IoU<0.3的建议框,由于负样本太多,采用hard negative mining的方法在负样本中选取有代表性的负样本
每一类的Bounding-box regression训练:
- 正样本:与Ground Truth的IoU最大,且IoU>0.6的Region Proposal
算法特点
- 使用Selective Search提取Proposes,然后利用CNN等识别技术进行分类。
- 使用识别库进行预训练,而后用检测库调优参数。
- 使用SVM代替了CNN网络中最后的Softmax,同时用CNN输出的4096维向量进行Bounding Box回归。
- 流程前两个步骤(候选区域提取+特征提取)与待检测类别无关,可以在不同类之间共用;同时检测多类时,需要倍增的只有后两步骤(判别+精修),都是简单的线性运算,速度很快。
存在问题
- 训练分为多个阶段,步骤繁琐: 微调网络+训练SVM+训练边框回归器。
- 训练耗时,占用磁盘空间大:5000张图像产生几百G的特征文件。
- 速度慢: 使用GPU, VGG16模型处理一张图像需要47s。
- CNN网络后面接的FC层需要固定的输入大小,限制网络的输入大小
- 候选区域会塞给CNN网络用于提取特征向量的,这会有大量的重复计算,造成的计算冗余
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!