本文最后更新于:14 天前
论文原文
链接:Fast R-CNN
RCNN通过卷积神经网络提取图像特征,第一次将目标检测引入了深度学习领域。
SPPNet通过空间金字塔池化,避免了对于同一幅图片多次提取特征的时间花费。
但是无论是RCNN还是SPPNet,其训练都是多阶段的。
- 首先通过ImageNet预训练网络模型,
- 然后通过检测数据集微调模型提取每个区域候选的特征,
- 之后通过SVM分类每个区域候选的种类,
- 最后通过区域回归,精细化每个区域的具体位置。
为了避免多阶段训练,同时在单阶段训练中提升识别准确率,Fast RCNN提出了多任务目标函数,将SVM分类以及区域回归的部分纳入了卷积神经网络中。
摘要
论文提出了一种快速的基于区域的卷积网络方法(fast R-CNN)用于目标检测。Fast R-CNN建立在以前使用的深卷积网络有效地分类目标的成果上。相比于之前的成果,Fast R-CNN采用了多项创新提高训练和测试速度来提高检测精度。Fast R-CNN训练非常深的VGG16网络比R-CNN快9倍,测试时间快213倍,并在PASCAL VOC上得到更高的精度。与SPPnet相比,fast R-CNN训练VGG16网络比他快3倍,测试速度快10倍,并且更准确。
Fast RCNN介绍
- 结合
SPP-Net改进RCNNROI Pooling:单层SPP-Net
- 多任务网络同时解决分类和位置回归
- 共享卷积特征
- 为
Faster RCNN的提出打下基础,提供了可能。
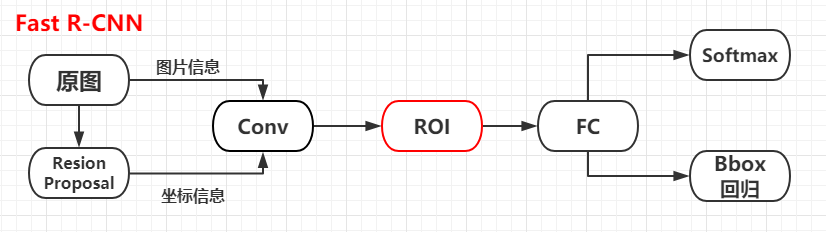
网络结构


ROI池化层
- 池化层的一种
- 目的就是为了将proposal抠出来的图像,然后resize到统一的尺寸。
- 操作流程如下:
- 根据输入的image,将ROI映射到feature map对应的位置
- 将映射后的区域划分为相同大小的sections(sections数量和输出的维度相同)
- 对每个sections进行max pooling的操作。
工作流程
- 输入:输入包括一张图片(224*244)和object proposal的集合(2000个),应该还是采用selective search来提取的。
- 卷积层:图片经过多个conv layer和max pooling layer得到整张图的feature map。
- RoI pooling layer:这层是借鉴SPPnet的SPP layer层,输入feature map和object proposal,然后为每个object proposal来提取在feature map上对应的特征,并使得输出都具有相同的size。
- 全连接层:将提取的特征输入两个全连接层(4096),把前边提取的特征综合起来
- 输出:Fast R-CNN的输出包括两部分:
- 一个是经过FC layer(21个node)+softmax输出的,主要是对object proposal进行分类的,一共包括21类,即20类物体加上1个背景类。这个就取代了之前的SVM分类器。
- 另一个是经过FC layer(84个node)+bbox regressor输出的,这个就是为21个类各输出4个值(21*4=84),而这4个值代表着精修的bounding box position。
总结
【优点】
- 比R-CNN和SPPnet具有更高的目标检测精度(mAP)。
- 训练是使用多任务损失的单阶段训练。
- 训练可以更新所有网络层参数。
- 不需要磁盘空间缓存特征。
【缺点】
- 虽然速度变得更快的,但是还是存在瓶颈:选择性搜索,在找出所有的候选框十分耗时间。
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!