本文最后更新于:14 天前
朴素贝叶斯的概念
朴素贝叶斯分类(Naive Bayes Classifier)是一种简单而容易理解的分类方法,看起来很Naive,但用起来却很有效。其原理就是贝叶斯定理,从数据中得到新的信息,然后对先验概率进行更新,从而得到后验概率。
就好比说我们判断一个人的品质好坏,对于陌生人我们对他的判断是五五开,如果说他做了一件好事,那么这个新的信息使我们判断他是好人的概率增加了。朴素贝叶斯分类的优势在于不怕噪声和无关变量,其Naive之处在于它假设各特征属性是无关的。而贝叶斯网络(Bayesian Network)则放宽了变量无关的假设,将贝叶斯原理和图论相结合,建立起一种基于概率推理的数学模型,对于解决复杂的不确定性和关联性问题有很强的优势。
条件概率
条件概率(Conditional Probability)是指在事件B发生的情况下,事件A发生的概率,用$P(A |B)$表示,读作在B条件下的A的概率。
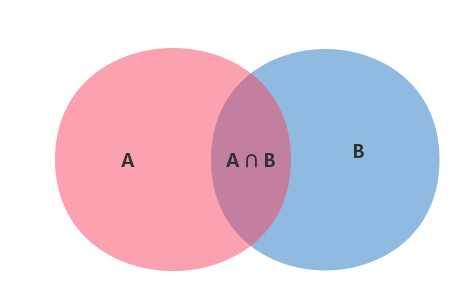
在上方的文氏图中,描述了两个事件A和B,与它们的交集A ∩ B,代入条件概率公式,可推出事件A发生的概率为
$P(A |B)=\frac{P(A⋂B)}{P(B)}$。
对该公式做一下变换可推得$P(A⋂B)=P(A | B)P(B)与P(A⋂B)=P(B | A)P(A)$,(P(B|A)为在A条件下的B的概率)。
同理可得$P(A |B)P(B)=P(B |A)P(A)$。
全概率公式
全概率公式是将边缘概率与条件概率关联起来的基本规则,它表示了一个结果的总概率,可以通过几个不同的事件来实现。
全概率公式将对一复杂事件的概率求解问题转化为了在不同情况下发生的简单事件的概率的求和问题,公式为
$P(B) = {\sum_{i=1}^n}P(A_i)P(B |A_i)$
假定一个样本空间S,它是两个事件A与C之和,同时事件B与它们两个都有交集,如下图所示:
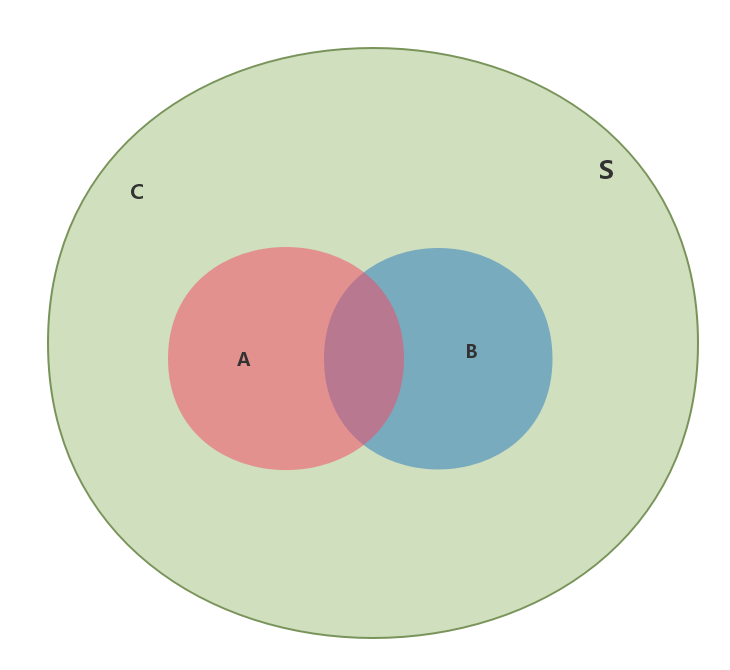
那么事件B的概率可以表示为$P(B)=P(B⋂A)+P(B⋂C)$
通过条件概率,可以推断出$P(B⋂A)=P(B |A)P(A)$,所以$P(B)=P(B |A)P(A)+P(B |C)P(C)$
这就是全概率公式,即事件B的概率等于事件A与事件C的概率分别乘以B对这两个事件的条件概率之和。
贝叶斯定理
贝叶斯公式:
$P(A|B) = \frac{P(B|A)P(A)}{P(B)}$
- $P(A |B)$:在B条件下的事件A的概率,在贝叶斯定理中,条件概率也被称为
后验概率,即在事件B发生之后,我们对事件A概率的重新评估。 - $P(B |A)$:在A条件下的事件B的概率,其实就是和上一条是一样的意思。
- $P(A)$与$P(B)$被称为
先验概率(也被称为边缘概率),即在事件B发生之前,我们对事件A概率的一个推断(不考虑任何事件B方面的因素),后面同理。 - $P(B |A)P(B)$被称为
标准相似度,它是一个调整因子,主要是为了保证预测概率更接近真实概率。 - 根据这些术语,贝叶斯定理表述为: 后验概率 = 标准相似度 * 先验概率。
朴素贝叶斯分类的原理
朴素贝叶斯分类是一种十分简单的分类算法,叫它朴素贝叶斯分类是因为这种方法的思想真的很朴素,朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
我们设一个待分类项$X=f_1,f_2,⋯,f_n$,其中每个f为X的一个特征属性,然后设一个类别集合$C_1,C_2,⋯,C_m$。
然后需要计算$P(C_1 |X),P(C_2 |X),⋯,P(C_m |X)$,然后我们就可以根据一个训练样本集合(已知分类的待分类项集合),然后统计得到在各类别下各个特征属性的条件概率:
$P(f_1 |C_1),P(f_2 |C_1),⋯,P(f_n |C_1),\, P(f_1 |C_2),P(f_2 |C_2),⋯ P(f_n |C_2), \\ P(f_1 |C_m),P(f_2 |C_m),⋯,P(f_n |C_m)$
如果$P(C_k |X)=MAX(P(C_1 |X),P(C_2 |X),⋯,P(C_m |X))$,则$X∈C_k$(贝叶斯分类其实就是取概率最大的那一个)。
朴素贝叶斯会假设每个特征都是独立的,根据贝叶斯定理可推得:$P(C_i |X)=\frac {P(X |C_i)P(C_i)}{P(X)}$,由于分母对于所有类别为常数,因此只需要将分子最大化即可,又因为各特征是互相独立的,所以最终推得:
$P(X | C_i)P(C_i)=P(f_1 |C_i)P(f_2 |C_i)…,P(f_n | C_i)P(C_i) \\ =P(C_i)\prod_{i=1}^nP(f_i |C_i)$
根据上述的公式推导,朴素贝叶斯的流程可如下图所示:
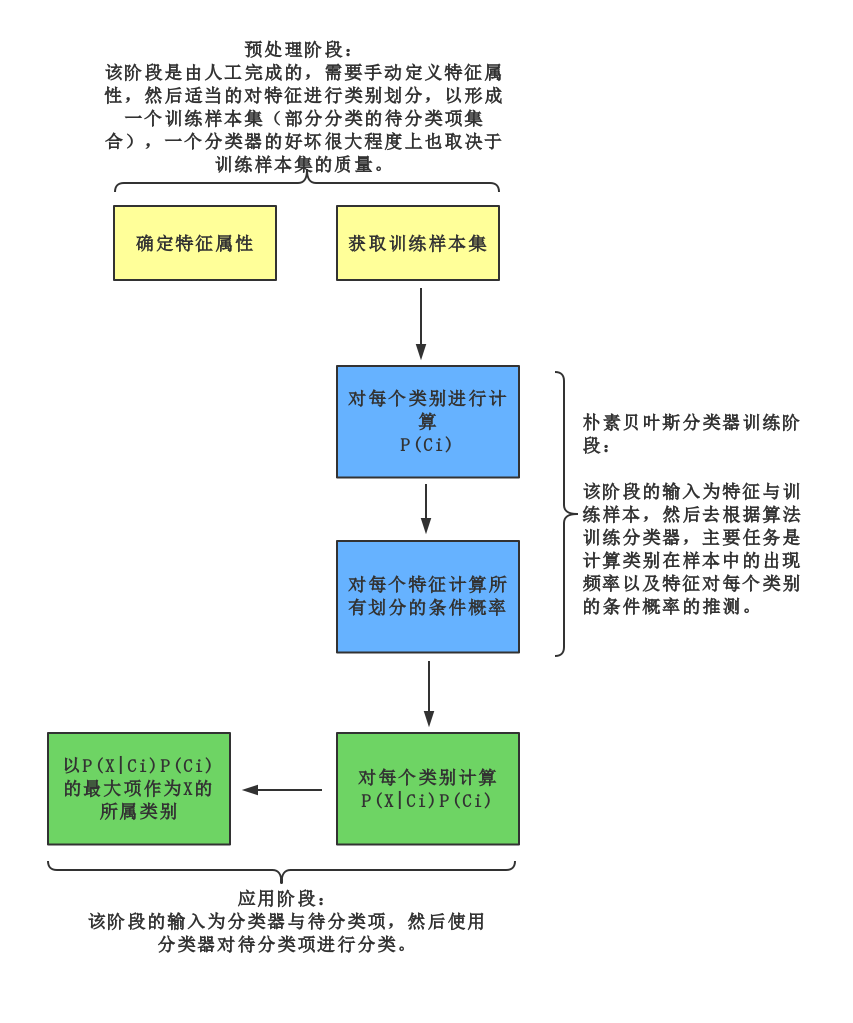
朴素贝叶斯的算法模型
在朴素贝叶斯中含有以下三种算法模型:
Gaussian Naive Bayes:适合在特征变量具有连续性的时候使用,同时它还假设特征遵从于高斯分布(正态分布)。假设我们有一组人体特征的统计资料,该数据中的特征:身高、体重和脚掌长度等都为连续变量,很明显我们不能采用离散变量的方法来计算概率,由于样本太少,也无法分成区间计算,那么要怎么办呢?解决方法是假设特征项都是正态分布,然后通过样本计算出均值与标准差,这样就得到了正态分布的密度函数,有了密度函数,就可以代入值,进而算出某一点的密度函数的值。
MultiNomial Naive Bayes:与Gaussian Naive Bayes相反,多项式模型更适合处理特征是离散变量的情况,该模型会在计算先验概率$P(C_m)$和条件概率$P(F_n |C_m)$时会做一些平滑处理。具体公式为$P(C_m)=\frac{T_{cm}+a}{T+ma}$
其中T为总的样本数,m为总类别数,$T*{cm}即类别为即类别为C_m$的样本个数,
a是一个平滑值。条件概率的公式为$P(F_n |C_m) = \frac{T_{cm}f_n+a}{T_{cm}+an}$
n为特征的个数,$$T_{cm}f_n$$为类别为$$C_m$$特征为$$F_n$$的样本个数。当平滑值
a = 1,被称作为Laplace平滑,当平滑值
a < 1,被称为Lidstone平滑。它的思想其实就是对每类别下所有划分的计数加1,这样如果训练样本数量足够大时,就不会对结果产生影响,并且解决了$P(F |C)$的频率为0的现象(某个类别下的某个特征划分没有出现,这会严重影响分类器的质量)。
Bernoulli Naive Bayes:Bernoulli适用于在特征属性为二进制的场景下,它对每个特征的取值是基于布尔值的,一个典型例子就是判断单词有没有在文本中出现。
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!